How AI product can perform depends on advanced algorithm as well as high quality data. It is believed that big companies have innate advantage in securing data, while start-ups often struggle. In fact, if the start-up is good at data hustling, it can get enough high quality data. We’ll be talking about some common ways:
人工智能产品的效果好坏,除了算法之外,依赖于高质量的数据。人们往往认为大公司在数据方面有天生的优势,而创业公司则举步维艰。实际上对创业公司来说,如果方法得当,也可以获得足够多高质量的数据,本文会和大家谈论一些常见的办法。
1 Inhouse Tagging
1 手动标注
It is the most common way to extract and tag raw data. Most CV, NLP and machine learning companies hire a special team to help tag data. Depends on the task, the so-called AI trainer would tag the part of data that AI need to recognize. The data manager or the AI product manager should be responsible for the speed and quality of data generation.
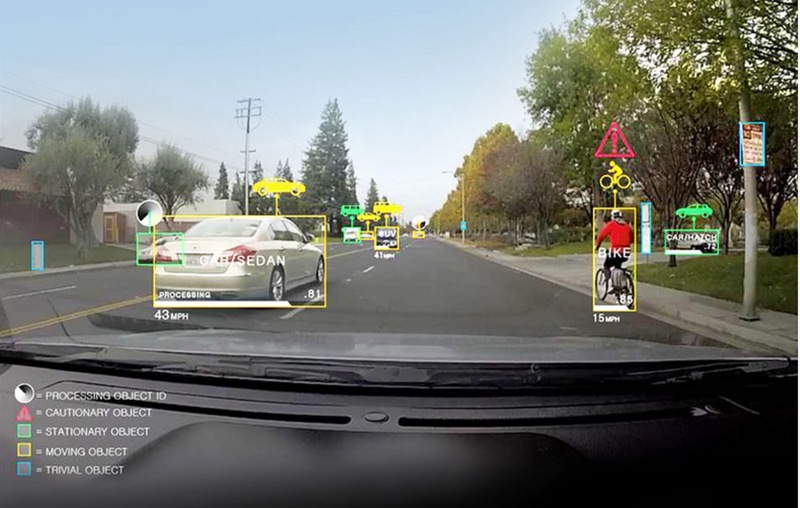
雇佣团队来对原始数据进行提取和标注可能是最常见的一种办法。大部分视觉、自然语言处理、机器学习的公司都雇佣了内部的团队来处理标注这些数据。视任务不同,标注人员将需要AI学习的内容标记出来,因此往往他们被称为AI训练师。以自动驾驶的标注为例,AI训练师需要标记出不同的物体的轮廓和特性,比如物体是否静止,是否值得注意等供AI学习。数据负责人需要最终对数据产生的速度和质量把关,让数据尽快进入良性循环。
It is the general way adopted by many companies. Data quality is usually good and the process is well-controlled. However, the cost can be high and it is difficult to tag lots of data whthin a short period of time.
内部团队的标注相对来说是一种通用的办法,质量较高也比较可控,几乎每个人工智能创业公司都会使用。但实现成本比较高,同时无法在短时间内快速标注大量数据。
2 Outsource or Crowdsourse
2 外包或者众包
Crowdsourse is a common way for generating large amounts of data. By
cooperating with platform like Amazon turks, the data manager should write detailed specification, communite with taggers and check the tagging quality.
众包是一种常用的生产大量数据的方法,通过和众包平台的合作,负责人撰写标注的判断标准,并和平台方沟通标注的流程并验收。国外比较出名的是Amazon Turks,国内也有一些大公司和创业公司在提供数据标注外包或者众包服务。
It is flexible to outsource the data tagging process and the cost is more reasonable. However in many cases, private data are too sensitive to share. Also, it might be difficult for taggers from different backgrounds to reach at the same standard.
众包的好处是相对比较灵活,成本也比较可控。但是一些公司内部私有的数据不适合公开标注,同时标注者水平也良莠不齐,不一定能处理复杂的标注任务。
3 User Tagging
3 用户主动参与
In some scenarios, users can give feedback while using products. The feedback can be used for tagging data. In the case of Facebook, product managers use feature to ensure account safety as well as tagging data.
在一些场景下,用户在使用产品的过程中可以主动提出反馈。这些反馈可以是很好的标注数据。比如在知乎的主页中,用户可以对某些内容填写不感兴趣,对其进行降权。或者在信息流应用中,用户在投诉时可以选择该内容是广告,色情或者敏感信息。
Using user tagged data has the benifits of low-cost and large quantity. But the data cleaning might be needed to filter out the dirty data points.
让用户产生数据相对来说是一种成本比较低同时能产生大量数据的办法,但是很多用户产生的数据不一定质量足够高,需要处理清洗以后才能使用。
4 Data Honeywell
4 数据蜜罐
In many products, users will create a lot of valuable data when engaging with the app. For example, Liulishuo, which origianlly develeped as a mobile app for Chinese adult spoken language improvement, has accumulated voices that be used for automatic speech recognition(ASR).
有一些公司的产品或者业务中,用户会在使用时无意地留下大量有价值的数据,而这些数据处理之后能产生很好的价值。比如定位在成人口语学习的英语流利说,虽然其主业务是帮助用户更好地发音,但是用户在练习口语时产生的语音是很好的标注数据,可以用来做语言识别等。
Data honeywell is an efficient way to produce data while it requires good timing and product ability. Also, since not all data are created equal, one must seperate gold from the sand.
数据蜜罐是一种高效产生数据的办法,但是对团队的产品能力和时机把握比较高。同时也不是所有产生的数据都是有价值的,需要仔细鉴别。
5 Public database
5 公有数据库
Universities and governments usually collect large quantity of data and open them in the internet for public use. One famous exmaple is ImageNet by Stanford professor Li Feifei, which accelerate the use of deep learning in CV. A start-up can start from open data base, train its model and then apply the model to wider application.
高校和政府机构常常拥有或者尝试搜集大量的数据,并将其公开在互联网上,供其他人加以应用。一个著名的例子是Stanford教授Li Feifei搜集的ImageNet,其推动了深度学习在图像识别的突破。公司也可以从公开的数据集着手,训练优化模型,以此为基础切入不同的使用场景。
It saves a lot of time and money to use public data. However, while public data is open to everyone, it is difficult to apply directly to product development.
公有数据库使用起来比较省力气,同时数据质量普遍也很高。但缺点是对于所有人都开放,较难直接拿来产品化,可以以此为基础调试模型。
6 Collaborate with 3rd party
6 和第三方公司合作
In the connected world, it is neither necessary nor realistic to product all the data one needs. Cooperating with other company to secure data can be a good way to get the benifits without the need to reinvent the wheels. For example, Alibaba has compressed its user behavioral data and released them as Zhima Credit, other companies can use the data in fraud detection in new users. 在互通共联的时代,所有数据都自己产生既不必要也不现实,可以和其它公司合作获得数据。大公司如像阿里巴巴提供了芝麻信用,可以用来处理风控相关的问题。同时很多实业公司或免费或付费也提供大量数据,如石油钻井公司提供了数据集可预测该区域有油的概率,电子商务公司可能有很多客户交互的聊天记录,挖掘以后都可能产生巨大的价值。
Similar to user generated data, the quality and value of data from 3rd-party varies. Given the huge amount of data owned by private companies, if used properly, great value can be extracted. 和用户产生的数据相似,从第三方获得的数据的质量和价值良莠不齐。但私有公司拥有的数据量如此之大,如果能有效利用的话可以产生巨大的价值。